Tech Blog #1
The Architecture
December 21, 2021
Taking a break from the normal product motivation theme of this blog to, instead, talk about some of the technology that makes Sound Off work. Obviously it’s impossible to cover everything in a single blog post. This entry focuses on the architecture of the backend and some of the underlying principles. Unlike other blog entries on Sound Off, this may not be accessible to non-technical folks.
Tech stack
Primary language: Java
Server framework: Playframework/AWS Lambda
Deployment/packaging
- AWS ECS
- AWS Lambda
Data storage
- AWS ElasticSearch
- Memcached (using AWS ElastiCache)
- AWS DynamoDB
- AWS S3
Other AWS technology used
- SNS
- Kinesis Firehose
- Lambda@edge
- SQS
- Rekognition
- ECS/EC2
- Cloudwatch
- Cloudfront
Other technologies used
- JSON
- JWT
- Websocket
- Docker
- Serverless
- Scala build tool (sbt)
- Jenkins
- Git via BitBucket
Architectural principles
Much of the motivation for the architecture of Sound Off was driven by a desire to achieve the following
- Allow for horizontal scaling to handle increased load
- Allow for 2-way communication between client and server
- Either end can generate data for the other
- Deliver consistent, low latency, responses to users
- Do as much work as possible on “our time” rather than the user’s
- Minimize the amount of manual tuning necessary to scale backend services
- Leverage AWS managed services in recognition of limited Sound Off engineering resources
- Namely I’m the only backend engineer and there are limits to my time!
The architecture
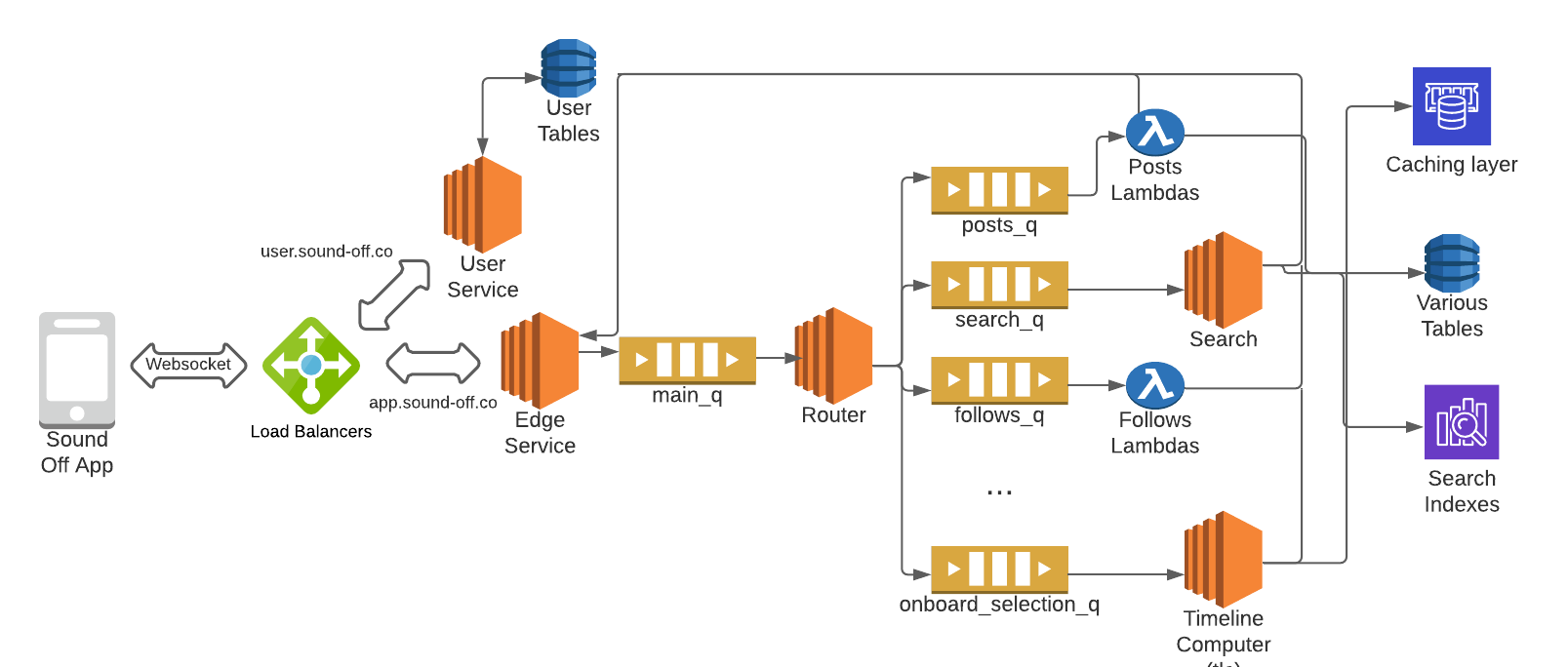
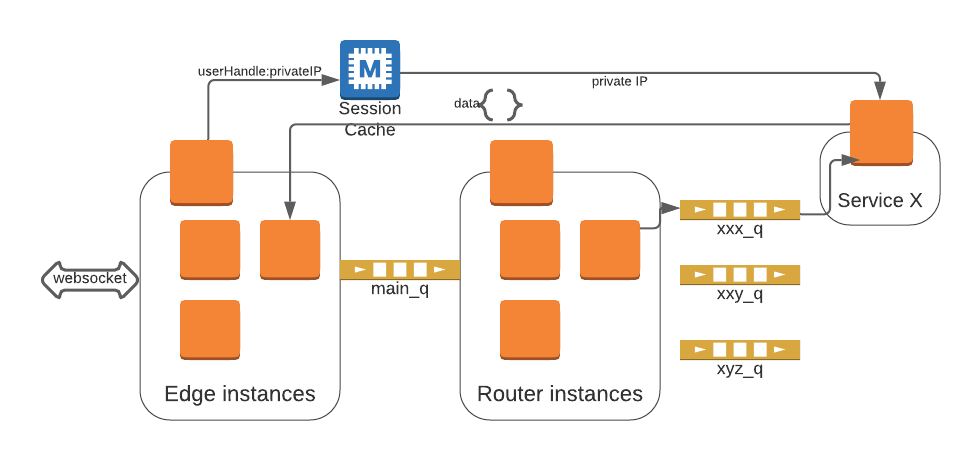
How does it work?
The diagram above elides many of the services and queues used in Sound Off’s backend. However it captures the basic setup.
- A websocket is used for full duplex communication between app and backend
- Authentication/Authorization (via issuance of a jwt token) is handled by the User service. The following authentication modes are supported
- AppleID
- Phone
Edge
- Once the user is authorized a websocket is established between the app and an instance of the Edge service
- One instance of the Edge holds the User’s websocket, the private IP of this instance is stored in Memcache
- The app sends JSON messages (in a format agreed upon by front and backend)
- Edge stores, in S3, any natively uploaded media
Edge forwards all message to a main_q
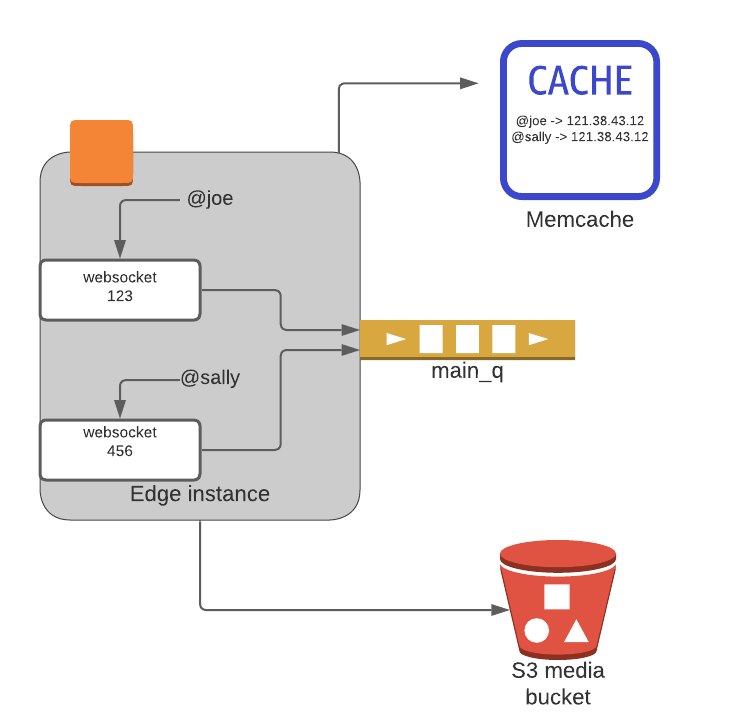
Router
- A Router service pulls messages from the main_q
- Routing handlers are registered on the Router service
- Handlers examine the MessageType as well as any relevant parts of the message to determine the following:
- Which, if any, MessageType specific queue to place the message on
- Any fan out to multiple queues
- Placement on other message senders (such as a Kinesis Firehose that archives data in S3)
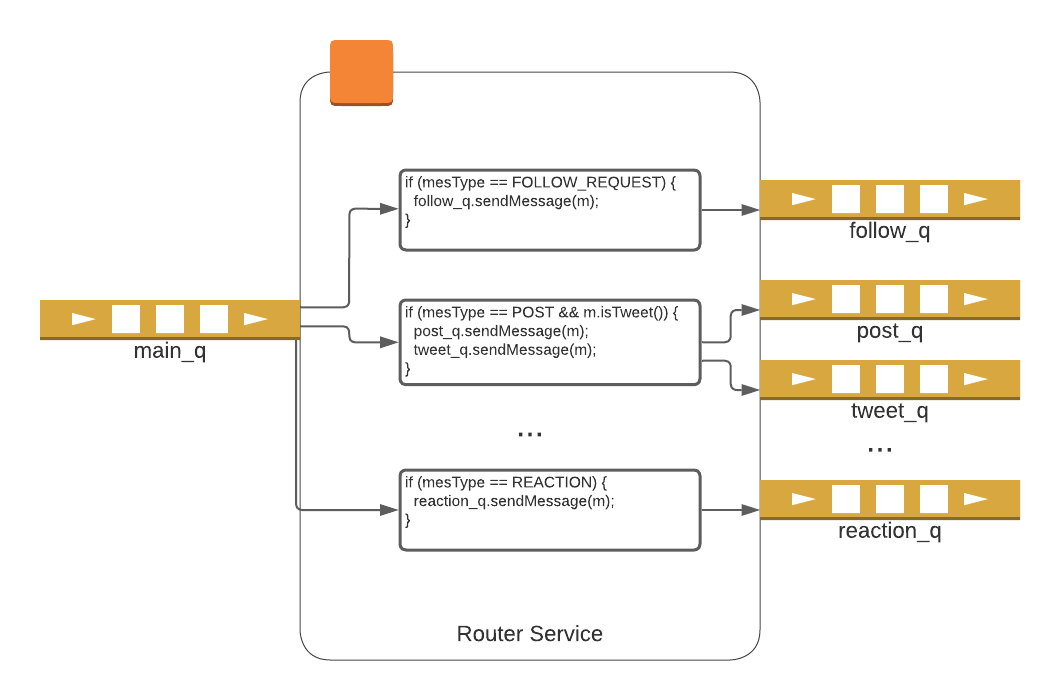
Service
- Messages are delivered to the relevant service. The service in turn does at least 1 of the following (sometimes more than 1)
- Persists data extracted from the message
- Transforms or forwards the message to another service(s)
Posts response data to the Edge instance with the in memory copy of the User’s websocket
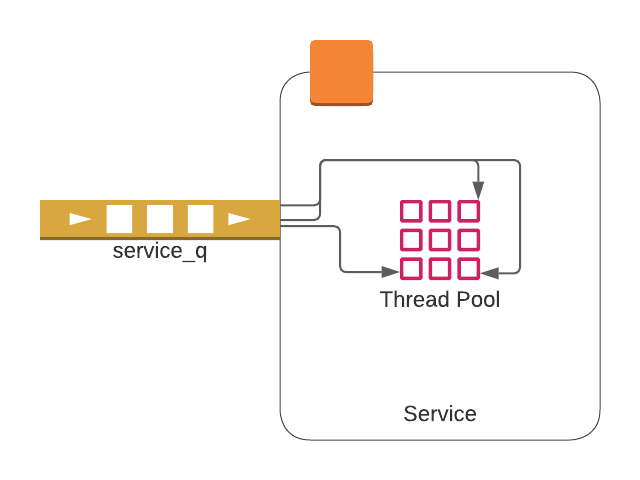
Handling a User message: A no wait approach
Many User generated messages result in messages either being sent to other Users on the platform or being sent back to the generating User (or sometimes both). Notice that in this architecture there are no REST requests between services. Messages are handled asynchronously. In a REST based architecture responses to requests end up on the server that generated the request. In this asynchronous model we still need to simulate this behavior by returning to the same Edge service instance that generated the message. This means that when it comes to responding to a User message, the Session Cache must be leveraged. The process is the following:
- A websocket is opened on an Edge instance
- Edge establishes an entry in the Session Cache mapping the User to its private IP
- Messages are routed and handled by the appropriate service
- Service extracts the relevant userHandles from the Message
- Service uses the extracted userHandles to find the private IP address of all Edge instances holding each of the websockets for each userHandle
- Note the way to determine if a User is online is to see if they currently have an entry in the cache
- Service issues a POST request to the Edge instance holding the User’s websocket
Edge instance places the POST body on the websocket which then pushes up to the User’s app
Precompute: Consistent response times, arbitrarily complicated algos
I spent much of my career at Netflix. In particular I worked on the system that served the User’s personalized homepage. In the event that a personalized homepage could not be computed within the readTimeout of the Client, we’d serve a fallback (non-personalized) response. We then began to notice something odd. Our customers that had been with us the longest were getting more fallback responses. This is the exact opposite of what you want. This effectively penalizes your most loyal users.
Precomputing the User’s experience facilitates two key advantages
- Cached experiences are retrieved with low latency for all users
- Algorithms personalizing the user’s experience can be arbitrarily complicated since they run outside the context of a User request
Sound Off leverages this experience by immediately starting with a precompute approach.
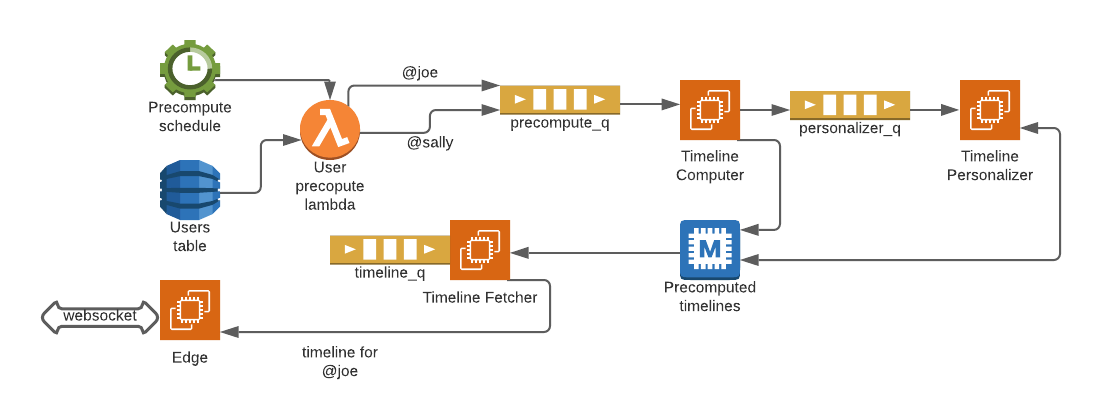
The diagram above shows the precompute process
- On a timed interval an AWS Lambda scans the User table for a list of all user handles
- A message is generated for each userHandle and is placed in a precompute_q
- Each message is picked up by an instance of the Timeline Computer (TLC)
- The TLC gathers all candidate content for the User’s Timeline and stores a chronologically timeline in Memcache
- The TLC generates another message (really just forwards the message that triggered it) to Personalization service
- The Personalization service reads the chronological timeline from Memcache
- Applies arbitrarily complicated personalization algorithms
- Stores the resulting timeline back in Memcache (using the User’s userHandle as the key)
- When the User opens a connection to Sound Off’s Edge a UserSession message is forwarded to the TimelineFetch service.
- The TimelineFetch service reads precomputed results from Memcache
- Applies real time fixups (removed deleted items, adds items that came in since precompute)
- Issues a POST to the Edge instance holding the User’s websocket
- The POST body, containing the User’s timeline, is then delivered to the Client via pushing up the websocket
Push vs. Pull: The advantage of queues
It’s worth revisiting the diagram above and discussing the push vs. pull approaches. In a traditional REST based system, work is pushed to service instances in the form of an HTTP request.
I say it’s pushed because a load balancer could naively choose an instance of the Service to respond to a request. The service instance may be busy or over capacity and running in a mode where requests are being queued up in local memory. This has a few disadvantages
- If the node goes down an arbitrarily large number of requests may be lost
- Instances can find themselves in unrecoverable states, with large internal queues of work, where they are processing work for which Clients have already walked away
- It takes observation/tuning to determine upon which Service metric one should use to autoscale to add/remove instances
- Newly provisioned instances can not relieve pressure on existing instances that have buffered/queued more work than they can ever recover from
- This means that old instances may have to be cycled which then puts more pressure on the new instances
- Back pressure manifests itself as read/connection timeouts
- Often this backpressure makes it all the way back to the client (and thus the User)
I refer to Sound Off’s model as a pull model. This model has a few advantages
- Decouples producer from consumer
- No need for a load balancer in front of a service. Service name/location is no longer relevant
- An arbitrary new message reader can be stood up without needing to reconfigure other services
- A service pulls work to itself as long as it has capacity in the form of a free thread
- Back pressure is handled by a growing queue, but there’s no slowdown adding to that queue
- Thus clients/users won’t see slowness at the point when they tap buttons to save/produce content
- They may, though, still see a slowdown when fetching data
- Autoscaling rules can be tuned to watch the visible items sitting in the queue and scale until that number drops to a low water mark
- The blast radius for an instance going down can be much smaller
- AWS SQS queues redeliver a message if not deleted within a fixed period of time. This operates as an effective, built in, retry mechanism
- New autoscaled instances are immediately able to relieve pressure by burning down the backlog of messages
Conclusion
No architecture is perfect and this architecture is no exception. Every architecture represents a series of tradeoffs. To recap, the tradeoffs made here:
- Prefer asynchronous vs. synchronous communication
- Prefer precompute computation(our time) vs. request time compute(user’s time)
- Prefer pulling work vs. pushing of work
With these elements in place Sound Off is well positioned for scale. Granted, building an unproven product for scale is an anti-pattern. Nevertheless part of the joy of building, whether it’s a company or a technology, is to take pride in one's craftsmanship. I enjoyed building this out and will describe more technical tradeoffs made in future blog posts. As usual thoughts and feedback are welcome. If you’re not on Sound Off, then find me on Twitter @joinSoundOff.